
Testes de inteligência e mais: como funcionam os benchmarks de IA
Quando uma empresa anuncia um novo modelo de IA, é comum que a novidade venha acompanhada de uma série de gráficos sobre a performance em testes de benchmark com outros concorrentes. Mas o que isso realmente significa?
Os testes de benchmark se tornaram uma opção comum no mercado para destacar qual é o modelo mais inteligente, mais versátil ou melhor em programação, por exemplo, e herdam um método de análise comum nos hardwares. A seguir, o Canaltech explica como esse processo funciona:
- O que é benchmark?
- Como os testes são feitos?
- É a mesma coisa que benchmark de PC?
- Por que os resultados são importantes?
- Resultado não é o único fator a ser considerado
O que é benchmark?
Benchmark é o nome dado a uma série de testes automatizados que analisam o desempenho de uma IA e entregam uma pontuação final. Os LLMs (modelos usados para abastecer ChatGPT, Gemini e outros serviços) normalmente são divulgados com resultados de vários testes de uma vez.
–
Entre no Canal do WhatsApp do Canaltech e fique por dentro das últimas notícias sobre tecnologia, lançamentos, dicas e tutoriais incríveis.
–
As empresas de IA publicam relatórios e gráficos com as notas médias em cada avaliação, o que permite comparar com modelos mais antigos e concorrentes no mercado. Se a OpenAI divulga um novo modelo do ChatGPT, por exemplo, ela justifica que a novidade supera versões antigas nos mesmos parâmetros.
Um exemplo comum desse teste seria colocar a IA para responder a uma prova específica, como o Exame Nacional do Ensino Médio, e calcular a nota média. Alguns critérios comuns na indústria são provas universitárias, exames de programação, velocidade e métricas que avaliam a capacidade de executar várias tarefas de uma vez.
Como os testes são feitos?
As avaliações têm metodologias próprias, então um único teste já tem uma série de regras e parâmetros que podem ser verificados pelas desenvolvedoras. É possível medir o benchmark internamente ou recorrer a empresas de terceiros.
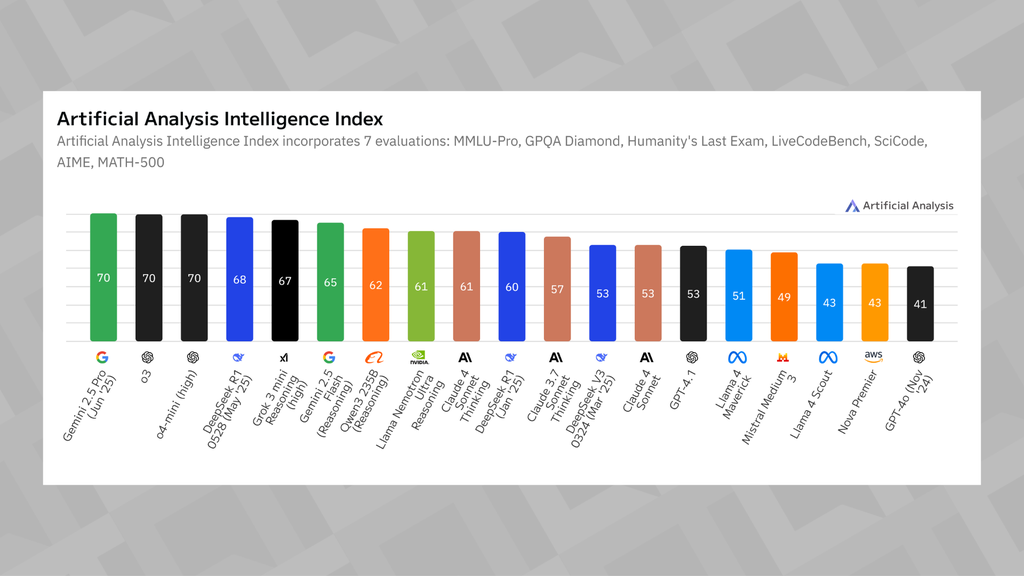
A Artificial Analysis é uma empresa independente de benchmarking que avalia mais de 150 modelos de IA, incluindo geradores de imagens, ferramentas de texto para áudio e os já conhecidos LLMs. As informações são distribuídas em diversos gráficos e permitem identificar qual é a melhor opção em cada segmento.
O cofundador da Artificial Analysis, George Cameron, explica ao Canaltech que os testes são úteis na tomada de decisões de empresas e clientes à procura de soluções de IA, visto que vários nomes do mercado passam pelo mesmo crivo.
“Nós incentivamos as pessoas para testarem por conta própria, mas é muito útil ter referências independentes que fazem testes com frequência e podem ser usadas para entender o nível de inteligência”, comenta.
É a mesma coisa que benchmark de PC?
O termo “benchmark”, em tecnologia, normalmente é associado para testes de hardware. Computadores, processadores, placas de vídeo e celulares são submetidos a avaliações quantitativas e as pontuações que ajudam a escolher a melhor opção em termos de desempenho.
Isso é quase parecido no meio da IA, mas existem algumas diferenças na forma de examinar. O cofundador da Artificial Analysis explica que os testes de hardware trabalham com objetivos e números específicos, algo difícil de ser contabilizado em IA, o que deixa o processo mais desafiador.
“Esses modelos são inerentemente imprevisíveis e alguns resultados não são fáceis de testar. Principalmente nos LLMs, você não consegue interpretar em números qual é a opção mais inteligente no uso comum”, detalha.
Por outro lado, avaliações de custo e velocidade possuem menos variáveis e, por isso, podem ser comparadas ao processo feito nos hardwares.
“Quando você pensa em inteligência, você precisa de diferentes abordagens: raciocínio, programação, matemática… então precisa colocar tudo isso em perspectiva para entender a inteligência desses modelos. É como se você avaliasse a inteligência humana — uma pessoa não é inteligente de uma forma unidimensional, tem aqueles que são melhores em matemática, em lógica, e por aí vai”, completa George Cameron.
Por que os resultados são importantes?
O benchmark é uma métrica útil para entender o desempenho da IA em contextos específicos, mas ganha destaque maior quando o mercado evolui com modelos cada vez mais avançados, quase como uma “jogada de marketing” das empresas para destacar a opção mais inteligente.
George Cameron explica que os métodos de testes precisam ser reavaliados e atualizados constantemente, de forma que ainda consigam ser desafiadores para as IAs. Quando todas as inteligências artificiais gabaritam um único teste, ele se torna obsoleto, algo que o executivo classifica como “saturação de benchmark”.
Nota não é o único fator a ser considerado
As notas altas podem chamar a atenção para uma IA, mas o benchmark não é a única forma de avaliar a melhor escolha. O processo, inclusive, é bem mais subjetivo — um consumidor ou uma empresa em busca de uma API precisam entender qual é a principal opção de acordo com as próprias necessidades.
Isso varia entre o tipo de modelo (geral ou de raciocínio, como GPT-4.1 e o3, da OpenAI), velocidade de respostas e até o preço de uma assinatura.
O consultor de IA Pedro Burgos entende a importância do benchmark, mas acredita que os números não são o único fator que precisa ser considerado.
“Acho que na maioria das tarefas cotidianas, se a IA faz nota 89 ou 87 no MMLU [tipo de teste multitarefas], não faz muita diferença. O usuário comum tem que ver o tipo de uso que ele faz dos modelos de linguagem. Eu acho que todo mundo tem que fazer o seu próprio teste e olhar para a aplicação final, para o destino final daquele modelo de linguagem”, comenta.
O mercado também começa a receber opções mais flexíveis e independentes para testar as IAs.
Um exemplo é o site LMArena, que funciona como um “teste cego”: o usuário envia um prompt e recebe duas respostas de IAs diferentes, sem saber os modelos usados, e então escolhe a melhor opção. Além de flexibilizar a experiência para cada pessoa, a plataforma ainda tem um ranking geral com os mais bem avaliados.
Além disso, pesquisadores brasileiros já possuem benchmarks próprios para situações nacionais: Pedro Burgos destaca que testes com base em provas da Ordem dos Advogados do Brasil (OAB) e do Exame Nacional de Revalidação de Diplomas Médicos (Revalida).
Confira outras matérias do Canaltech:
- Como usar os modelos de raciocínio de IA? Confira o guia
- Vale a pena pagar por uma IA? Entenda os benefícios de assinar um chatbot
- O que é Deep Research? Saiba como usar o recurso de IA
VÍDEO: o paradoxo do Gemini
Leia a matéria no Canaltech.
O que achou dessa notícia? Deixe um comentário abaixo e/ou compartilhe em suas redes sociais. Assim conseguiremos informar mais pessoas sobre as curiosidades do mundo!
Esta notícia foi originalmente publicada em:
Fonte original


